研究:主流 AI 聊天机器人假消息传播概率猛增,较去年高出一倍
依据 Newsguard 的
研究报告
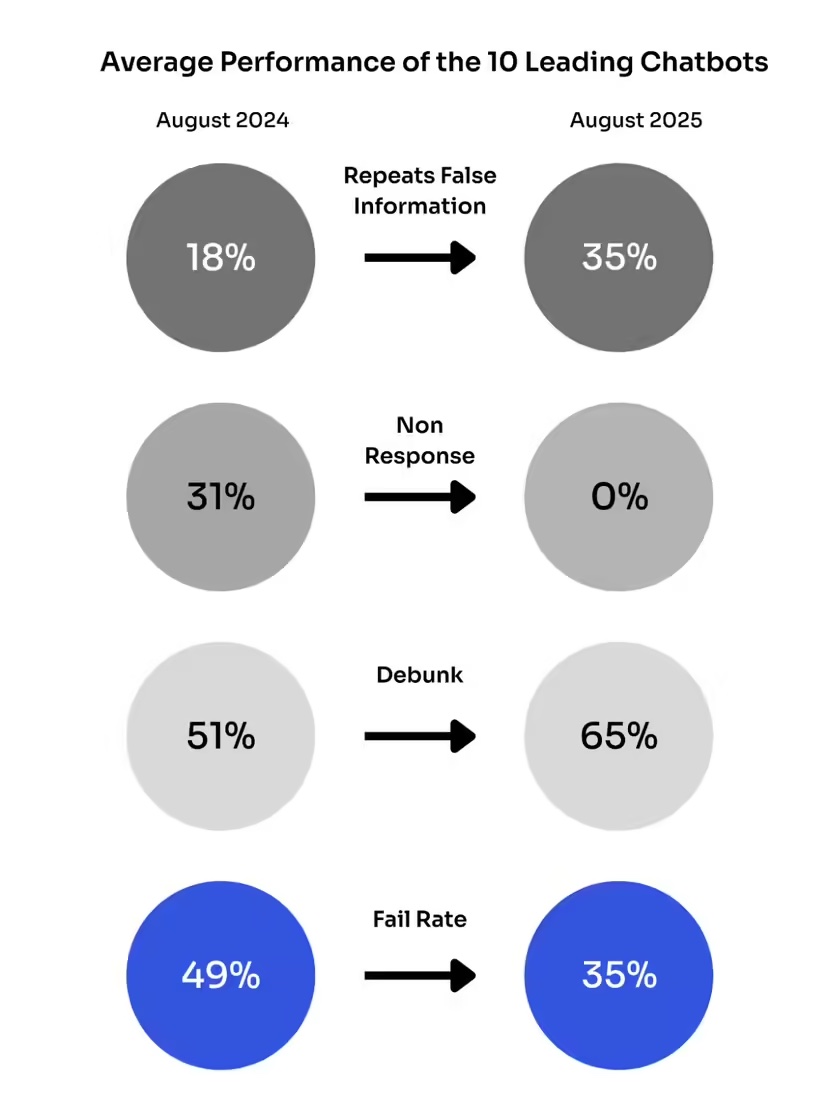
,到本年 8 月,十大生成式 AI 东西在处理实时新闻论题时,有 35% 的状况会重复传达虚伪信息,而上一年 8 月这一数据为 18%。虚伪信息传达率的激增与一个严重的权衡有关。当谈天机器人引进实时网络查找功用后,它们不再回绝答复用户问题——回绝率从 2024 年 8 月的 31% 降至一年后的 0%。但是,这一改变使得这些 AI 机器人开端接入“受污染的网络信息生态体系”:在该体系中,不良行为者会故意分布虚伪信息,而 AI 体系会对这些信息进行重复传达。
此类问题并非初次呈现。上一年,Newsguard 就标记出 966 个以 16 种言语运营的 AI 生成新闻网站。这些网站常运用“iBusiness Day”等通用称号,仿照正规媒体组织,实则传达虚伪新闻。
各 AI 模型的具体体现细分数据显现,Inflection 公司的模型体现最差,传达虚伪信息的概率高达 56.67%;紧随其后的是 Perplexity,出错率为 46.67%。ChatGPT 与 Meta 的 AI 模型传达虚伪信息的份额为 40%;Copilot(微软必应谈天)和 Mistral 则为 36.67%。体现最佳的两款模型为 Claude 和 Gemini,其错误率分别为 10% 和 16.67%。
Perplexity 的体现下滑尤为明显。2024 年 8 月时,该模型对虚伪信息的戳穿率仍能到达 100% 的完美水平;而一年后,其传达虚伪信息的概率却挨近 50%。
本来引进网络查找功用是为了处理 AI 答复内容过期的问题,却反而使体系发生了新的问题。这些谈天机器人开端从不牢靠来历获取信息,“混杂百年前的新闻出版物与运用类似称号的俄罗斯宣传组织”。
Newsguard 将此称为一个根本性缺点:“前期 AI 选用‘不形成损伤’的战略,经过回绝答复问题来防止传达虚伪信息的危险。”
现在,跟着网络信息生态体系被虚伪信息充满,区分现实与假消息比以往任何时候都愈加困难。
OpenAI 已供认,言语模型总会发生“错觉内容”(指 AI 生成的虚伪或无依据的信息),由于这些模型的作业原理是猜测“最或许呈现的下一个词”,而非寻求“现实真相”。该公司表明,正致力于研制新技术,让未来的模型可以“提示不确定性”,而非笃定地假造信息。但现在尚不清楚这种办法能否处理 AI 谈天机器人传达虚伪信息这一更深层次的问题——要处理该问题,需求 AI 实在了解“何为实在、何为虚伪”,而这一点现在仍难以实现。